© 2005 Ubicom, Inc. All rights reserved.
- 30 -
www.ubicom.com
SX20AC/SX28AC
15.0 INSTRUCTION SET
As mentioned earlier, the SX family of devices uses a
modified Harvard architecture with memory-mapped
input/output. The device also has a RISC type architec-
ture in that there are 43 single-word basic instructions.
The instruction set contains byte-oriented file register, bit-
oriented file register, and literal/control instructions.
Working register W is one of the CPU registers, which
serves as a pseudo accumulator. It is a pseudo accumu-
lator in a sense that it holds the second operand,
receives the literal in the immediate type instructions, and
also can be program-selected as the destination register.
The bank of 31 file registers can also serve as the pri-
mary accumulators, but they represent the first operand
and may be program-selected as the destination regis-
ters.
15.1 Instruction Set Features
1. All single-word (12-bit) instructions for compact code
efficiency.
2. All instructions are single cycle except the jump type in-
structions (JMP, CALL) and failed test instructions
(DECSZ fr, INCSZ fr, SB bit, SNB bit), which are two-
cycle.
3. A set of File registers can be addressed directly or indi-
rectly, and serve as accumulators to provide first oper-
and; W register provides the second operand.
4. Many instructions include a destination bit which se-
lects either the register file or the accumulator as the
destination for the result.
5. Bit manipulation instructions (Set, Clear, Test and Skip
if Set, Test and Skip if Clear).
6. STATUS Word register memory-mapped as a register
file, allowing testing of status bits (carry, digit carry, ze-
ro, power down, and timeout).
7. Program Counter (PC) memory-mapped as register file
allows W to be used as offset register for indirect ad-
dressing of program memory.
8. Indirect addressing data pointer FSR (file select regis-
ter) memory-mapped as a register file.
9. IREAD instruction allows reading the instruction from
the program memory addressed by W and upper four
bits of MODE register.
10.Eight-level, 11-bit push/pop hardware stack for sub-
routine linkage using the Call and Return instructions.
11.Six addressing modes provide great flexibility.
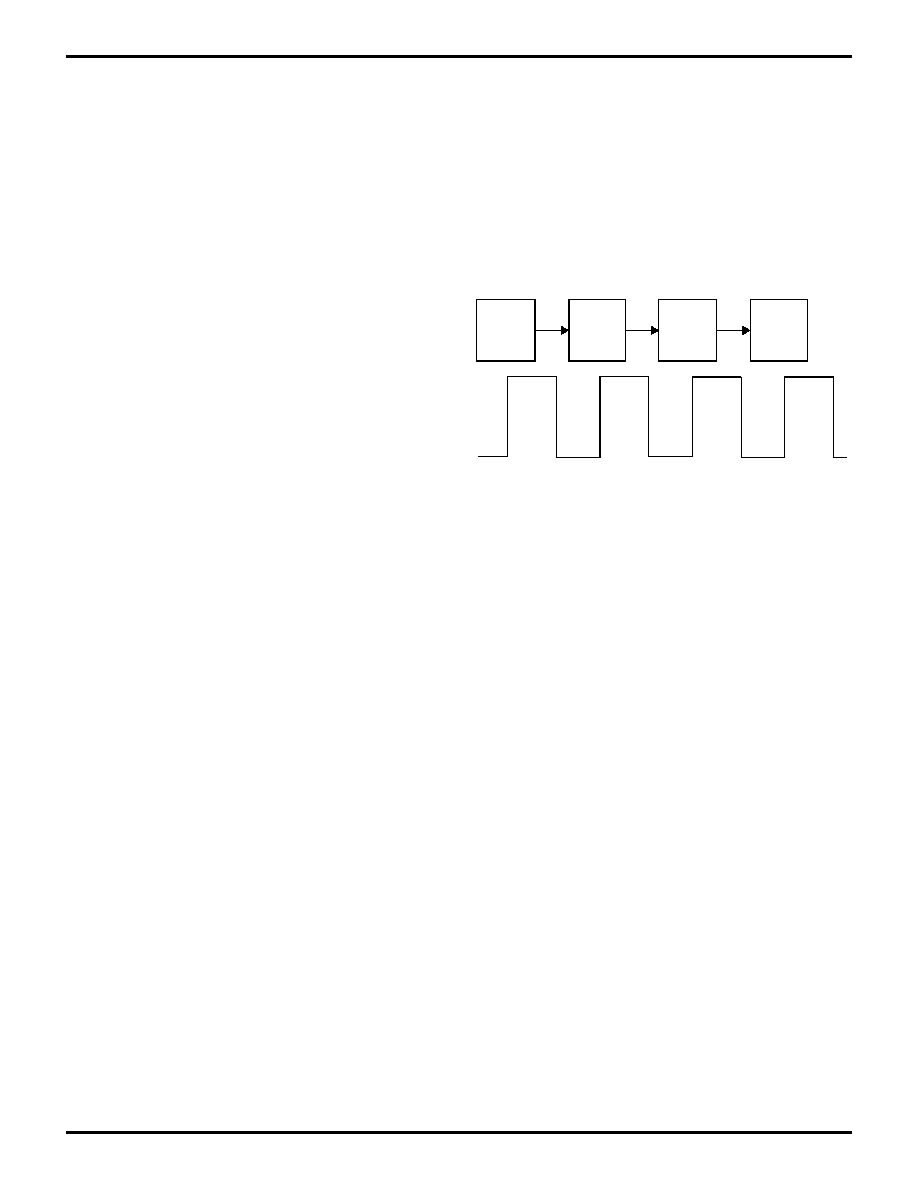
15.2 Instruction Execution
An instruction goes through a four-stage pipeline to be
from the program memory on the first clock cycle. On the
second clock cycle, the first instruction is decoded and
the second instruction is fetched. On the third clock cycle,
the first instruction is executed, the second instruction is
decoded, and the third instruction is fetched. On the
fourth clock cycle, the first instruction's results are written
to its destination, the second instruction is executed, the
third instruction is decoded, and the fourth instruction is
fetched. Once the pipeline is full, instructions are exe-
cuted at the rate of one per clock cycle.
Instructions that directly affect the contents of the pro-
gram counter (such as jumps and calls) require that the
pipeline be cleared and subsequently refilled. Therefore,
these instruction take more than one clock cycle.
The instruction execution time is derived by dividing the
oscillator frequency by either one (turbo mode) or four
(non-turbo mode). The divide-by factor is selected
through the FUSE Word register.
15.3 Addressing Modes
The device support the following addressing modes:
Data Direct
Data Indirect
Immediate
Program Direct
Program Indirect
Relative
Both direct and indirect addressing modes are available.
The INDF register, though physically not implemented, is
used in conjunction with the indirect data pointer (FSR) to
perform indirect addressing. An instruction using INDF as
its operand field actually performs the operation on the
register pointed by the contents of the FSR. Conse-
quently, processing two multiple-byte operands requires
alternate loading of the operand addresses into the FSR
pointer as the multiple byte data fields are processed.
Examples:
Direct addressing:
Indirect Addressing:
Figure 15-1.
Pipeline and Clock Scheme
mov
RA,#01
;move "1" to RA
mov
FSR,#RA
;FSR = address of RA
mov
INDF,#$01
;move "1" to RA
Fetch
Decode
Execute
Write
Clock
Cycle
1
Clock
Cycle
2
Clock
Cycle
3
Clock
Cycle
4